
Partial sorted list scheduler - pslist
pslist is a fair O(1) Linux CPU scheduler with a very easy design. The concept of a partial sorted list only works for scheduling problems, I will explain the datastructure later in this post, first some benchmark results.
Benchmark Results
The results were measured on a dual core AMD Athlon X2 5000+ at 2.6Ghz with cool’n’quiet disabled. CFS and pslist were measured based on Linux 3.6, without stable updates. All plots include 0.95 confidence intervals. All measurements were repeated at least 5 times and 10 minutes. Depending on the relative standard errors of the results, the measurements were repeated until a maximum runtime of 60 minutes per benchmark. If you have questions about the setup, ask in the comments.
Here are some benchmarks with significant differences between both schedulers. We begin with the influence of complexity classes, pslist O(1), CFS O(log n). The yield benchmark tries to make as much ‘sched_yield’ calls as possible, for a limited amount of time. The calls are executed in parallel with the given number of threads. The plot shows the number of iterations reached, more is better.

You can clearly see the advantage of pslist, which has a very low time consumption. List operations are much cheaper than red-black-tree operations. Especially with an increasing number of threads, pslist reaches significantly more iterations than CFS.
The same complexity class influence is visible in the hackbench benchmark. With 400 processes, pslist is again better than CFS. This plot shows the runtime necessary to complete the benchmark, so less is better.

Some more suprising results are read and write results of unixbench. Reads are significantly better, while writes are worse. Perhaps this is a unixbench specific phenomenon.


You can download all generated data and plots in the ‘Material’ section below.
pslist Datastructure
A partial sorted list is basically a list, which is completely unsorted. It maintains a pointer to the list item in the middle. This middle-item is used to find the position for a new list item. If the new one is bigger, it is added at the tail of the list, else the new item is added in the middle.
As you can see this very simple design is only suitable for scheduling, because you have to sort at another position. In my case, the real sorting is happening while running the current entity. It is running as long as the next element has a bigger runtime/vruntime. This ensures a fair behavior between all tasks. If this property is not fullfilled, the scheduler is not fair. This is a big issue with pslist if the currently running task stops running before it reaches a bigger vruntime than the next entity, which occures when an entity is preempted or calls the sched_yield function.
The whole concept is not as strict as CFS, which leads to another characteristic behavior of pslist. pslist compensates vruntime through running as long as the vruntime is not more than the next one. The non strict order of entities leads to higher wait times and probably higher latencies.
You can see an example progress of a pslist in the following figure. Each row represents one scheduling step. The numbers are virtual runtimes, which show the progress of the specific task. Arrows show the movement of items in the pslist.
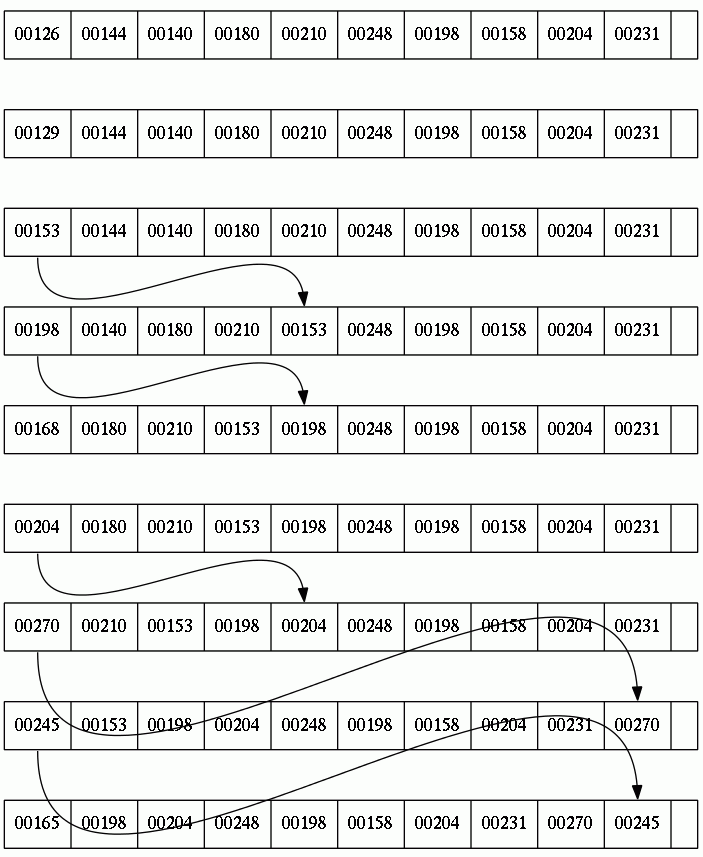
This is a pslist simulation. You can see the full simulation of 100 steps by clicking on the image. The maximum difference between vruntimes is limited. The limit is dependent on the number of tasks and the runtime granularity of the tasks.
Material
Conclusion
pslist is a very simple fair O(1) scheduler, but there can be some issues in special cases. The kernel patches I created are very stable, I used it for some time on my desktop machine. The unsorted list raises very restrictive limitations for further improvements.
This scheduler may increase the performance for some workloads, so I will update the patches for some future kernel versions, but it is not suitable for all systems.